 qz thoughts
qz thoughtsWeb Log Tools
As in tools for web server logs, not the web logs commonly called "blogs".
In the early 2000s, I was doing a lot of very specific log analysis. At the time I was "webmaster" for a site with ads. To justify ad sales, the company paid for a web server log audit service. This provided the main log reports looked at by the company, but sometimes I'd be called on to explain things. So I had to dive into the logs and examine them myself.
Enter logprint. Today this tool is not going to be widely useful, instead
people will use an ELK stack and define a grok rule in the logstash part
of ELK. But initial release of logstash was 2010, long after I wrote
logprint.
What logprint does is parse log files of various formats — I
defined four that I've had to work with, adding more is an excerise
regular expression writing, same as with grok — into columns.
Some of those columns can be sub-parsed. For example, the Apache request
line column can be broken down into a method ("GET", "POST", "HEAD",
etc), a URI (the actual requested resource) and an optional protocol
(not present for HTTP 0.9 or present as "HTTP/1.0" or "HTTP/1.1").
After parsing the line, it can be filtered: only consider requests that
succeeded (2xx), and were over 200,000 bytes; then selectively print
some of the columns for that entry, say date, referer, URI.
# Apache "combined" has referer as a column ("common" does not)
# status >= 200 and status <= 299 is any 2xx response
# @uri will only be the local file name, discarding a full hostname
# on the request line and CGI parameters
logprint -f combined \
-F 'status>=200' -F 'status<=299' -F 'bytes>200000' \
-c date,referer,@uri
Things like parsing the file part into URI when you get a request with
the full URL on the GET line is an unusual need, but I needed it then
and it is still useful now. The same parsing rules for a full URL there
are also available for parsing Referer: headers, which was once useful
for pulling out search terms used from referring search engines.
So logprint is a very handy slice and dice tool for web logs. It can
be combined with another tool I wrote, adder which aims to be a full
featured "add values up" tool. You can feed in columns of numbers and
get columns of sums. You can feed in columns of numbers and get a sum
per line. You can feed in value and keyword and get sums per keyword.
That last one is rather useful in combination with logprint.
# using Apache "common" format, find lines with status 200,
# print bytes used and the first directory component of the URI file part
# pipe that to adder,
# suppress column headers,
# use column 0 as value to add,
# and column 1 as label
logprint -f common --filter status=200 -c bytes,file:@path1 $log |
adder -n -b 1 -r 0
That gets output like this (although this was sorted):
/u 14415354750 /favicon.ico 3311323662 /i 655750249 /qz 272329622 /apple-touch-icon.png 218913277 /index.html 62583501 /jpeg 49580565 /qz.css 38188009
So simple to see where the bytes are coming from. Looking at that, I decied I really should better compress the "apple-touch-icon.png". I'm not sure I can get "faveicon.ico" smaller, at least not with the features it has now. And the CSS and other icons in /i/ also got some compression.
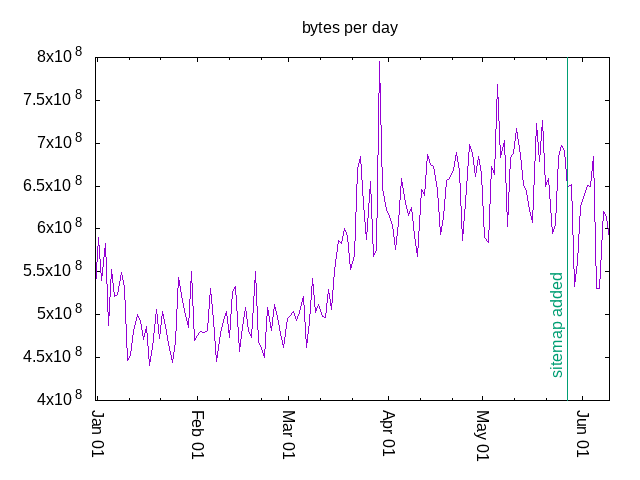
Then I looked at bytes per day to see if adding a sitemap helped. It does, but the difference is slight, easy to lose in the weekly cycle. Usage really picked up in April, didn't it?
$ cat by-day-usage
#!/bin/sh
log="$1"
if [ ! -f "$log" ] ; then echo "$0: usage by-day-usage LOGFILE[.gz]"; exit 2 ; fi
shift;
logprint -f common --filter status=200 -c bytes,date $log $@ |
adder -n -b 1 -r 0
And graphed with gnuplot
So I'm
publishing these log tool scripts
for anyone interested in similar simple
log slicing and dicing. It's not awstats or webalizer but it's not
trying to be either.